前言
本节我们来分析LEFT JOIN和NOT EXISTS,简短的内容,深入的理解,Always to review the basics。
LEFT JOIN...IS NULL和NOT EXISTS分析
之前我们已经分析过IN查询在处理空值时是基于三值逻辑,只要子查询中存在空值此时则没有任何数据返回,而LEFT JOIN和NOT EXISTS无论子查询中有无空值上处理都是一样的,当然比较重要的是利用LEFT JOIN...IS NULL来检查NULL。基于二者返回的结果集是一样的,下面我们开始直接用前面节所创建表来进行测试。在BigTable和SmallerTable上首先未创建索引
USE TSQL2012GODBCC FREEPROCCACHEDBCC DROPCLEANBUFFERSSET STATISTICS IO ONSET STATISTICS TIME ONSELECT BigTable.ID, SomeColumn FROM BigTable LEFT OUTER JOIN SmallerTable ON BigTable.SomeColumn = SmallerTable.LookupColumn WHERE LookupColumn IS NULLSELECT ID, SomeColumn FROM BigTableWHERE NOT EXISTS (SELECT LookupColumn FROM SmallerTable WHERE SmallerTable.LookupColumn = BigTable.SomeColumn)
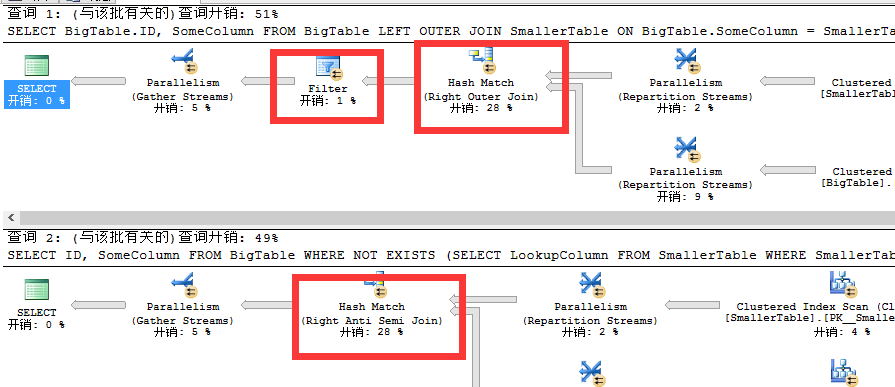
二者执行CPU Time和elapsed Time如下

我们看到上述查询计划未创建索引之前二者在开销上接近一致,而LEFT JOIN....IS NULL则首先进行哈希匹配中的右外部联接,然后就是过滤,换句话说是LEFT JOIN....IS NULL会直接完全JOIN,然后再对重复数据进行过滤,而NOT EXISTS则是直接利用哈希匹配中的右半联接,关于半联接我们在前面也已经说过,此时若有重复数据直接只取一个。所以LEFT JOIN....IS NULL和NOT EXISTS二者对于重复数据一个通过两部操作完成先完全JOIN后进行过滤,而另外一个则是直接通过右半联接过滤。所以对于此二者最大的不同在于:当使用LEFT JOIN.....IS NULL时,SQL还没有那么聪明,仅仅只检查一次,因此它需要通过完全JOIN和过滤来完成,而NOT EXISTS则是在JOIN时就进行过滤。
在看二者执行CPU TIME和elapsed TIME时间,没有太大的差异。接下来我们再来创建索引看看。
CREATE INDEX idx_BigTable_SomeColumnON BigTable (SomeColumn) CREATE INDEX idx_SmallerTable_LookupColumnON SmallerTable (LookupColumn)
看看二者的查询执行计划
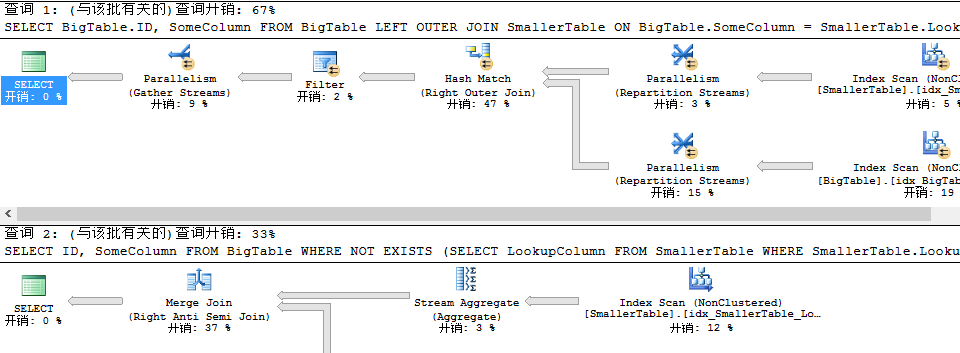

此时我们通过看到上述查询执行计划,我们能够清楚的看到LEFT JOIN....IS NULL还是完全JOIN然后在过滤,只是创建了索引之后性能改善了一点而已,但是不同于LEFT JOIN...IS NULL的NOT EXISTS的计划执行情况不同于未创建索引,此时首先利用了流聚合然后哈希匹配中的右半联接变成了合并联接中的右半联接,我们一个个来看,这个Stream Aggregate(流聚合)是什么鬼,对于此流聚合我是不了解的,不能装懂,我们接下来具体讲讲流聚合,至于为什么每当查询计划出现一个新的名词都要去详细了解下的原因,相信看过我SQL Server本系列的童鞋知道,每一节的内容都非常短,不会出现阅读疲劳,而且是精讲,我重头系统学习SQL Server是为了对SQL Server中所有涉及到对性能调优有关的地方以及一些基础知识都会去过一遍,以便后续再出现性能调优不至于束手无策。好了,回到话题,我们看看Stream Aggregate。
Stream Aggregate
msdn上有关概念如下:Stream Aggregate运算符按一列或多列对行分组,然后计算查询返回的一个或多个聚合表达式。此运算符的输出可供查询中的后续运算符引用和/或返回到客户端。Stream Aggregate 运算符要求输入在组中按列进行排序。如果由于前面的 Sort 运算符或已排序的索引查找或扫描导致数据尚未排序,优化器将在此运算符前面使用一个 。在 SHOWPLAN_ALL 语句或 SQL Server Management Studio 的图形执行计划中,GROUP BY 谓词中的列会列在 Argument 列中,而聚合表达式列在 Defined Values 列中。
通过上述定义仅仅只是知道Stream Aggregate是用对行或者列进行聚合,至于什么时候在查询计划中出现流聚合,什么时候利用流聚合来提高查询性能都是不得而知,我们接下来一起探讨下。上述着重在于【分组】然后进行【聚合】计算,基于这点我们来看看使用Stream Aggregate的三种场景。
(1)聚合汇总
USE TSQL2012GOSELECT COUNT(custid) AS cutid, SUM(empid) AS empidFROM Sales.Orders

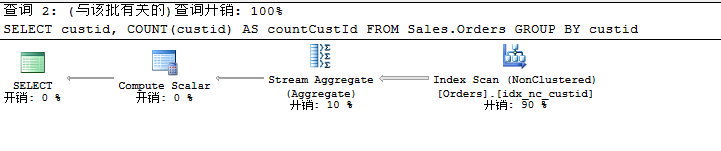
(2)先分组,再聚合汇总
USE TSQL2012GOSELECT custid, COUNT(custid) AS countCustIdFROM Sales.OrdersGROUP BY custid
(3)DISTINCT汇总
USE TSQL2012GOSELECT DISTINCT custidFROM Sales.Orders

上述查询使用通过DISTINCT,实际上是对cutid进行了分组。以上是用到了Stream Aggregate的场景,当然聚合还有另外一种就是哈希匹配聚合,后续会再进行补充。我们再来理解Stream Aggregate定义,我们将定义概括为对输入进行排序后,接下来进行分组然后再进行聚合计算。在上述(2)和(3)中都是进行了分组,但是没有排序,实际上内部已经默认实现了排序,我们看下在(3)中表中custid数据,如下
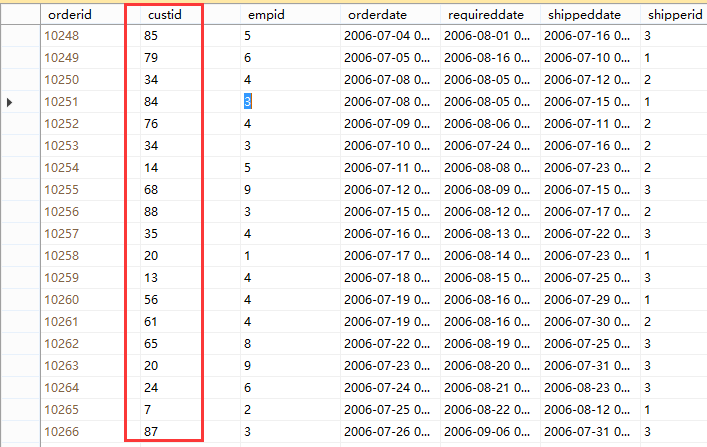
当进行DISTINCT之后

但是在(3)中没有进行聚合,为什么会进行流聚合呢?实际上在流聚合中存在状态变量,状态变量具体个数根据聚合个数而定,此状态变量用来设置结果集,当进行分组后对应的数据进行保存,此时对应的状态变量为0,当匹配到对应数据时此时状态变量加1,所以上述(3)中可以说隐式进行了聚合计算,只是每条数据对应的状态变量为0而已,到了这里就不难解释,只进行了排序,分组而没有进行聚合计算的原因。关于Stream Aggregate都知道的一个例子则是我们在利用SqlDataReader记性读取数据时,可以说是读取流记录,如果我们需要汇总结果集时,此时每当Read时,其内部的状态变量都会加1最终返回汇总和到客户端。在这里我们只是简单讲讲Stream Aggregate,后续会一并讲讲Hash Aggregate。我们继续回到LEFT JOIN....IS NULL和NOT EXISTS话题,当我们创建索引之后此时LEFT JOIN....IS ISNULL执行时间是NOT EXISITS的两倍多。到此,关于LEFT JOIN...IS NULL和NOT EXISTS就此结束,我们同样下个基本结论。
LEFT JOIN...IS NULL和NOT EXISTS性能分析结论:当我们需要找到子查询中不匹配的行并且列为可空时,此时用NOT EXISTS,当需要找到子查询中不匹配的行,此时列不为空时可以用NOT EXISTS或者NOT IN。
由于LEFT JOIN..IS NULL对于不匹配的行不会立即进行返回而先需要完全JOIN后过滤,尤其是当有多个条件时,LEFT JOIN...IS NULL可能会更加影响查询性能。
总结
本节我们学习了LEFT JOIN..IS NULL和NOT EXISTS的性能分析,下节我们进入这几节内容的综合篇,综合比较NOT IN VS NOT EXISTS VS LEFT JOIN...IS NULL终极篇。简短的内容,深入的理解,我们下节再会。